Related Publications
Bitstream-based Neural Network for Scalable, Efficient and Accurate Deep Learning Hardware, Hyeonuk Sim and Jongeun Lee**, Frontiers in Neuroscience, 14, pp. 1198, Frontiers, December, 2020.
Cost-effective Stochastic MAC Circuits for Deep Neural Networks, Hyeonuk Sim and Jongeun Lee**, Neural Networks, 117, pp. 152-162, Elsevier, September, 2019.
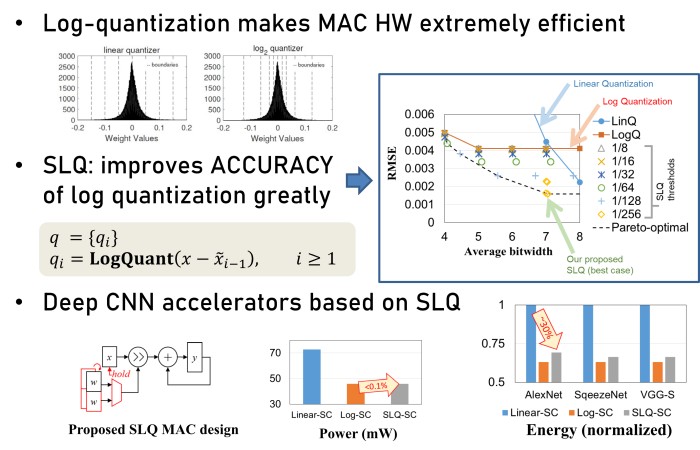
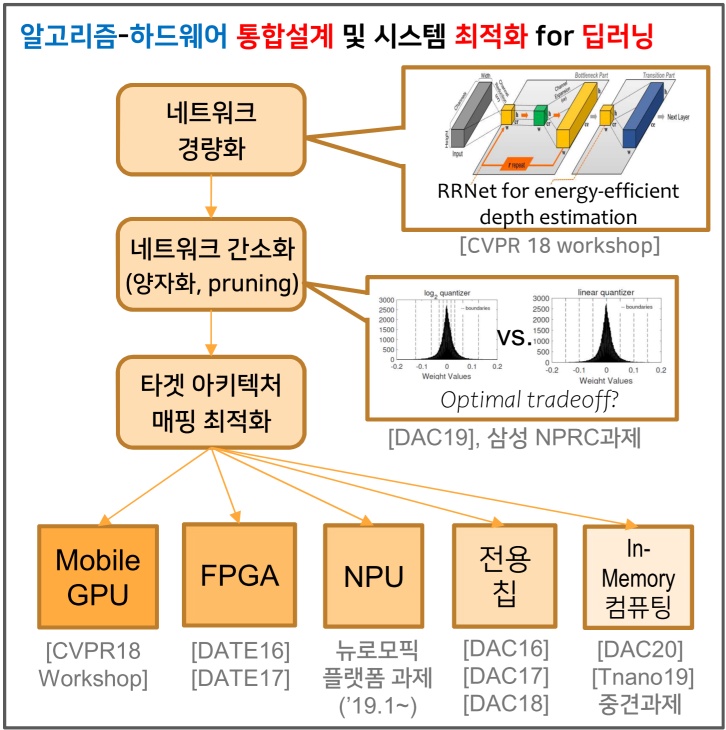
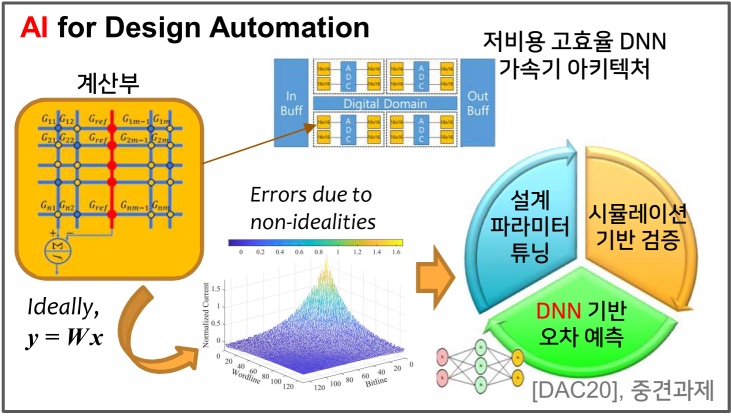
Successive Log Quantization for Cost-Efficient Neural Networks Using Stochastic Computing, Sugil Lee, Hyeonuk Sim, Jooyeon Choi and Jongeun Lee**, Proc. of the 56th Annual ACM/IEEE Design Automation Conference (DAC), pp. 7:1-7:6, June, 2019.
Log-Quantized Stochastic Computing for Memory and Computation Efficient DNNs, Hyeonuk Sim and Jongeun Lee**, Proc. of the 24th Asia and South Pacific Design Automation Conference (ASP-DAC), pp. 280-285, January, 2019.
An Efficient and Accurate Stochastic Number Generator Using Even-distribution Coding, Aidyn Zhakatayev, Kyounghoon Kim, Jongeun Lee** and Kiyoung Choi, IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), 37(12), pp. 3056-3066, December, 2018.
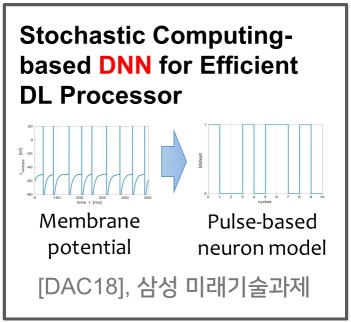
DPS: Dynamic Precision Scaling for Stochastic Computing-Based Deep Neural Networks, Hyeonuk Sim, Saken Kenzhegulov and Jongeun Lee**, Proc. of the 55th Annual ACM/IEEE Design Automation Conference (DAC), pp. 13:1-13:6, June, 2018.
Sign-Magnitude SC: Getting 10X Accuracy for Free in Stochastic Computing for Deep Neural Networks, Aidyn Zhakatayev, Sugil Lee, Hyeonuk Sim and Jongeun Lee**, Proc. of the 55th Annual ACM/IEEE Design Automation Conference (DAC), pp. 158:1-158:6, June, 2018.
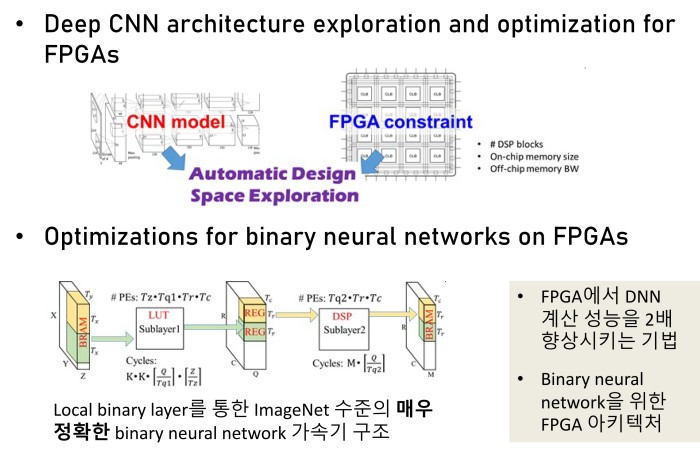
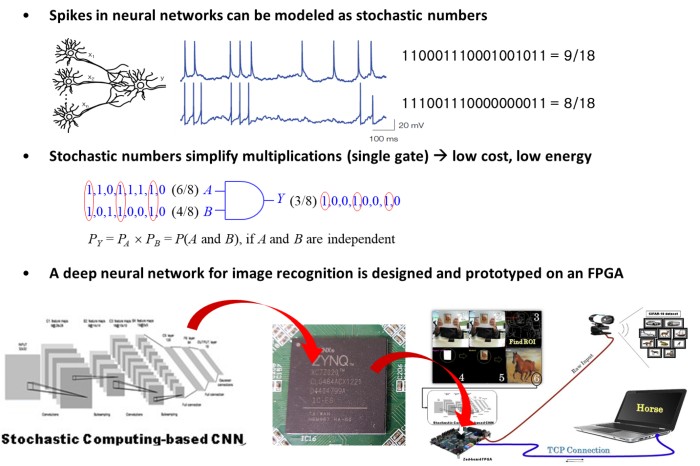
FPGA Implementation of Convolutional Neural Network Based on Stochastic Computing, Daewoo Kim, Mansureh S. Moghaddam, Hossein Moradian, Hyeonuk Sim, Jongeun Lee** and Kiyoung Choi, Proc. of IEEE International Conference on Field-Programmable Technology (FPT), pp. 287-290, December, 2017.
Accurate and Efficient Stochastic Computing Hardware for Convolutional Neural Networks, Joonsang Yu, Kyounghoon Kim, Jongeun Lee* and Kiyoung Choi, Proc. of IEEE International Conference on Computer Design (ICCD), pp. 105-112, November, 2017.
A New Stochastic Computing Multiplier with Application to Deep Convolutional Neural Networks, Hyeonuk Sim and Jongeun Lee**, Proc. of the 54th Annual ACM/IEEE Design Automation Conference (DAC), pp. 29:1-29:6, June, 2017.
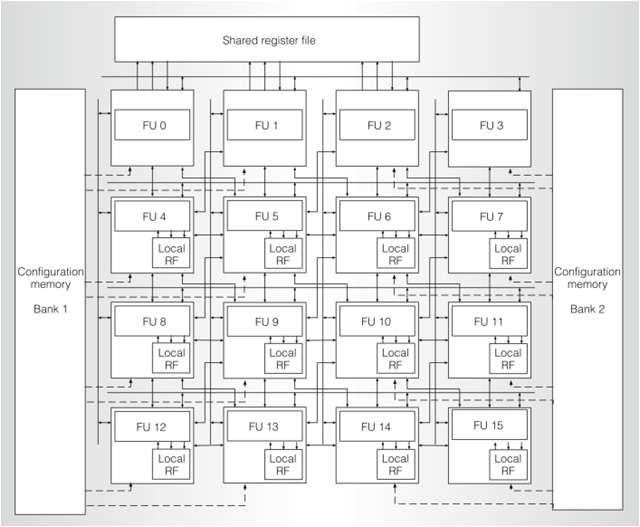
Scalable Stochastic-Computing Accelerator for Convolutional Neural Networks, Hyeonuk Sim, Dong Nguyen, Jongeun Lee** and Kiyoung Choi, Proc. of the 22nd Asia and South Pacific Design Automation Conference (ASP-DAC), pp. 696-701, January, 2017.