Hello,
We’re looking for undergraduate internship students who are interested in the following topics.
– Tensor processor design
– Hardware design with Python
– Prototyping custom hardware on a real FPGA board
– Quantization of neural networks
– AI processors
This internship is different from usual internship in that it is very well structured and students will be able to learn key, important concepts and skills in the broad area of hardware / software co-design through hands-on practice.
Opportunities to participate in industry-collaborative projects (such as with Samsung Advanced Institute of Technology (SAIT)) are open as well.
Drop by the lab or professor’s office or send an email if you’re interested.
Due: June 26, 2022.
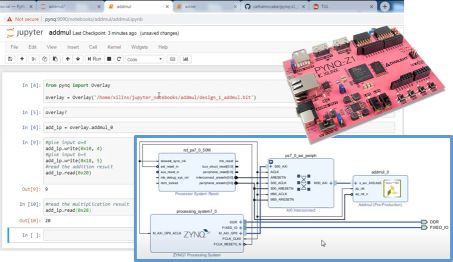
Tensor Processor Design with Python and FPGA Board
We’re accepting new graduate students.
Background doesn’t really matter, but it helps a lot if you are good at either
- software programming (e.g., C++, advanced level in Python)
- hardware design (e.g., Verilog/VHDL/SystemC development of a sizable system)
- strong math or analytical thinking
- or have a very good GPA from a reputable school (e.g., UNIST).
So whether you’re EE or CSE major (or something else),
Please apply or contact me if you’re interested and qualified.
We’re a leading research group on edge-based AI,
and our graduates go to Samsung, LG, international start-ups, etc.
We’re also recruiting undergraduate interns.
Please apply!
We have a couple of papers just accepted:
DAC 2026 paper (B-Flex): kudos to Hyunsung Jeong and others. This is a collaboration with a KAIST team (Prof. Jung). The paper is about a new, revolutionary way to an old problem — the flip-flop design problem — and sheds reusable insights on how to approach EDA problems in the age of AI.
FCCM 2026 paper (AccelOrb): congrats to Sunjae Kim, Gwanhong Park, Jiwoo Lim, and Faaiz Asim. This is a short paper, but mostly done by our undergraduate research team, who did very excellently during the last year. I’m really happy that the long and hard work has culminated in a good publication.
CGRA4HPC 2026 (IPDPS-W) paper (FlowSpec): kudos to YoungNo Kim, Hyeonseo Kim, Eunseok Cho, and San Aung! CGRA4HPC is a new workshop collocated with IPDPS, focusing on CGRAs and novel dataflow architectures, etc. This is also a culmination of a collaboration between our undergraduate research interns and graduate members, and we have many great plans going forward as well!
The homepage was a little less functional during the last months due to the server relocation and related issues. Now it’s fully functional again. Thanks for your patience and continued interest!
Our recent paper on NPU compiler work specialized for modern binarized neural networks is accepted to an upcoming conference, ASP-DAC 2024. Kudos to Minjoon and Faaiz as well as the entire ICCL team.
Using the latest version. You may have noticed slightly different menu.
Anyway, enjoy gitlab!
The ICCL lab gave a presentation at the 60th DAC, July 2023.
The title of the DAC paper was, “NTT-PIM: Row-Centric Architecture and Mapping for Efficient Number-Theoretic Transform on PIM,” authored by Jaewoo Park, Sugil Lee and Jongeun Lee.
We also got our paper accepted to ICCAD, 2023.
The title of the ICCAD paper is, “Hyperdimensional Computing as a Rescue for Efficient Privacy-Preserving Machine Learning-as-a-Service,” authored by Jaewoo Park, Chenghao Quan, Hyungon Moon and Jongeun Lee.
Congratulations to those who contributed to DAC/ICCAD papers!
Congratulations! Our paper titled “Squeezing Accumulators in Binary Neural Networks for Extremely Resource-Constrained Applications,” authored by Azat and Jaewoo has been accepted to the 41st International Conference on Computer-Aided Design (ICCAD 2022), which is held in San Diego, California, in October 30 – November 3.
Unlike the previous papers trying to reduce the multiplication overhead of neural network hardware, this paper asks a different question that is, in binarized neural networks and extremely low-precision quantized neural networks, what is the real bottleneck in hardware implementation? It turns out that accumulators now take a lion’s share in terms of not only area but more power dissipation, and we propose a novel method to minimize accumulator overhead.


Congratulations! Our paper titled “Non-Uniform Step Size Quantization for Post-Training Quantization” authored by Sangyun and Jounghyun as well as our graduate, Hyeonuk, has been accepted to the European Conference on Computer Vision (ECCV) 2022, which is held in Tel Aviv, Israel, in October 23-27.
Unlike the previous papers focusing on better training for quantized neural networks, this paper proposes a radically new concept called subset quantizer, which is based on the idea that by selecting the best subset of quantization levels from a given set of predefined levels, we can increase the representation capability of a quantizer while ensuring the hardware friendliness of arithmetic operations. The concept of the subset quantizer itself was developed by Dr. Hyeonuk Sim together with his advisor, Dr. Jongeun Lee, during the last year of his Ph.D. program.

Minsang Yu joined the lab in February, 2022, as a master’s program student. He majored in electronic engineering. Before joining the lab, he worked as an assistant researcher at Korea Electronics Technology Institute (KETI) and developed the IoT Edge Device for sensor data synchronization for digital twin. His research interests include AI hardware accelerator design and electronic design automation with machine learning.
Minuk Hong joined the lab in February, 2022, as a master’s program student. He majored in electronic engineering.
His research interests include hardware accelerator design with HDL and HLS for AI application.

