The HPC lab will present a new paper in the 18th Reconfigurable Architectures Workshop, which is held in a larger conference, IPDPS, May 16-19, Anchorage, Alaska, USA. It’s about how to speed up communication between a CPU and an application-specific coprocessor.
Welcome, new members in CSE! We’ll have a welcome party today for people in CSE labs. Both newcomers and old members are welcomed.
Parallel processing, or multi-core compilation, is rather a challenge than a blessing, since it means the era of free ride is over. When the hardware performance kept doubling every 18 months, the same software could be run twice as before by running it on a new hardware. But now it is no longer true, unless the software can somehow exploit the increased parallelism by the new machine.
There are many challenges including how to compile applications, or in particular, how to map code and data onto various heterogeneous as well as homogeneous processor cores, and manage them efficiently. The management must include aspects of not only performance optimization, but of thermal management, energy and power optimization (such as Dynamic Voltage and Frequency Scaling), and reliability (such as soft error resilience). These multi-dimensional, multi-objective problems require innovative ideas and approaches on architecture, compiler, computer-aided design, operating system, and algorithm levels.
In ICCL Lab, we are particularly looking at data management problems for distributed memory architectures such as the Cell processor architecture, where simple scratchpad memories are used instead of power-hungry caches to save power.
Publications
- Software-based Register File Vulnerability Reduction for Embedded Processors, Jongeun Lee and Aviral Shrivastava, ACM Transactions on Embedded Computing Systems (TECS), 13(1s), pp. 38:1-38:20, ACM, November, 2013.
- Return Data Interleaving for Multi-Channel Embedded CMPs Systems, Fei Hong, Aviral Shrivastava, and Jongeun Lee, IEEE Transactions on Very Large Scale Integration Systems (TVLSI), 20(7), pp. 1351-1354, IEEE, July, 2012.
- Static Analysis of Register File Vulnerability, Jongeun Lee and Aviral Shrivastava, IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), 30(4), pp. 607-616, IEEE, April, 2011.
- A Compiler-Microarchitecture Hybrid Approach to Soft Error Reduction for Register Files, Jongeun Lee and Aviral Shrivastava, IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), 29(7), pp. 1018-1027, IEEE Press, July, 2010.
- Cache Vulnerability Equations for Protecting Data in Embedded Processor Caches from Soft Errors, Aviral Shrivastava, Jongeun Lee*, and Reiley Jeyapaul, ACM SIGPLAN Notices (LCTES ’10), 45(4), pp. 143-152, April, 2010.
- A Software-Only Solution to Use Scratch Pads for Stack Data, Aviral Shrivastava, Arun Kannan, and Jongeun Lee*, IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), 28(11), pp. 1719-1727, November, 2009.
Two U-WURF students have visited HPC lab for one month. Mr. Ahn explored ASIP (Application-Specific Instruction-set Processor) design approach to accelerate the speed of software-based solutions. Mr. Lee demonstrated the power of GPU computing for general computing (so called GPGPU) for two applications, ie., matrix multiplication and genetic algorithm. Congrats for successfully completing the U-WURF program. Some of the details of their research can be found in the HPC wiki.
Chang Won Lee participated in U-WURF 2010. His wiki page.
Byung Jun Ahn participated in U-WURF 2010. His wiki page.
Introduction to GPU Super-computing Programming.
This 3+ hour seminar will cover the following topics:
1. What is GPU Programming
2. Scalar Processor vs. Vector Processor
3. Clustering/Clustered Computer programming
4. Vector Programming
5. CUDA
6. OpenCL
When & where: Fri 1/14, 2 ~ 6 pm. @ E205
Device miniaturization is causing significant problems in semiconductor reliability. One particularly nasty problem is what is called transient fault — transient as opposed to permanent because these kinds of faults or errors happen only temporarily. So you may experience this kind of error one time, but you may not experience the same error when you do the same operation again, thus no reproducibility. This can pose a very serious challenge to “testing”, and equally challenging is how to mitigate the effects of such transient errors at runtime. The question that is traditionally asked is i) how to detect such errors and ii) how to correct computation once they are detected.
A very different approach to the same problem is, to try to reduce the rate of such errors.. say to 1/100 times, because if the errors happen very rarely it may not be a problem. This can be done as easily as by recompiling the program… Sounds intriguing? For m0re detail, please check this out: “A compiler optimization to reduce soft errors in register files,” ACM SIGPLAN Notices, Vol. 44, No. 7, pp. 41-49, by Jongeun Lee and Aviral Shrivastava, 2009.
Register file (RF) is extremely vulnerable to soft errors, and traditional redundancy based schemes to protect the RF are prohibitive not only because RF is often in the timing critical path of the processor, but also since it is one of the hottest blocks on the chip, and therefore adding any extra circuitry to it is not desirable. Pure software approaches would be ideal in this case, but previous approaches that are based on program duplication have very significant runtime overheads, and others based on instruction scheduling are only moderately effective due to local scope. We show that the problem of protecting registers inherently requires inter-procedural analysis, and intra-procedural optimization are ineffective. This paper presents a pure compiler approach, based on inter-procedural code analysis to reduce the vulnerability of registers by temporarily writing live variables to protected memory. We formulate the problem as an integer linear programming problem and also present a very efficient heuristic algorithm. Our experiments demonstrate that our proposed technique can reduce the vulnerability of the RF by 33~37% on average and up to 66%, with a small 2% increase in runtime. In addition, our overhead reduction optimizations can effectively reduce the code size overhead, by more than 40% on average, to a mere 5~6%, as compared to highly optimized binaries.
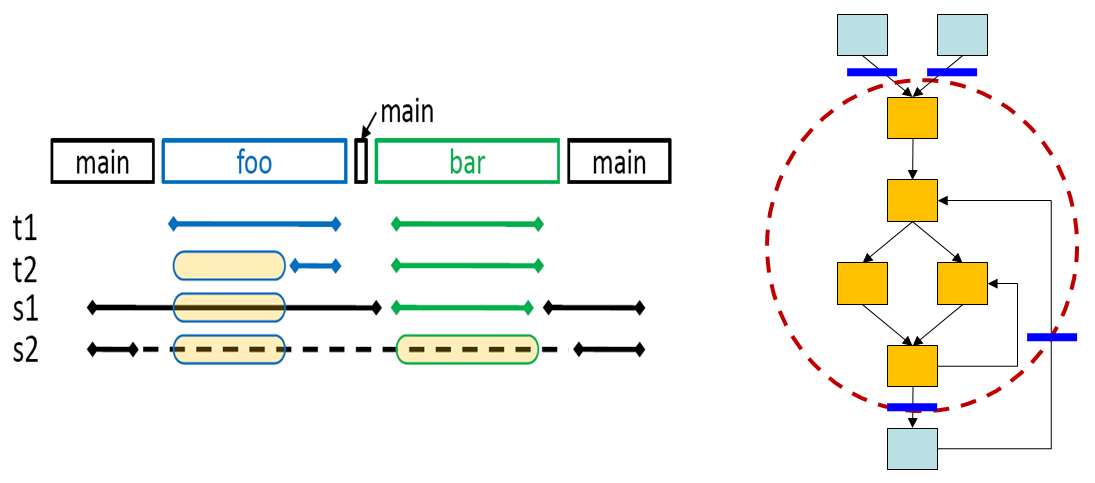
Dynamic vs. Static view of a program. Transient error can be best defined/understood in the dynamic view (left) of the program, but compilers can only see the static view (right), thus the challenge of this approach.
The best method, which is also recommended by Michael Shell, is to use this:
\enlargethispage{-X.Yin}
somewhere at the top of the first column of the last page. The last page gets effectively shortened by the “X.Yin” amount.

