|
|
You are here: Foswiki>Main Web>SimpleScalar (11 Sep 2014, AtulRahman)Edit Attach
-- ChangWonLee - 2011-01-10

matrix의 크기가 L2 cache의 size와 같아서 부분합을 구하는 부분에서 행 단위로 뛰는 참조를 하기때문에 miss rate가 상당할줄 알았지만 수행 결과 miss rate가 L1 9.1%, L2 2%로 생각보다 크지 않았다. L2 cache를 설정할 때, block당 64byte로 4-way를 하여 1024개의 line이 존재하게 하였다. Matrix의 행에 대한 연산은 순차적으로 접근하기 때문에 miss rate이 매우 작을것이므로 대부분의 cache miss는 행단위일 것이다. 행 단위로 접근하는 연산은 3중첩 for문에 의해서 256*256*256 = 16777216이 된다. 이 프로그램을 simulation하는데 데이터를 위한 access 횟수는 L1 data(186063025) + L2(17039552)로 총 203102577개이다. 따라서 행단위 연산에서 무조건 miss가 난다고 할 때 행단위의 miss rate는 256^3/(데이터 메모리 access횟수) = 0.08이다. 하지만, 이렇게 무조건적인 miss가 발생할리는 없으므로 0.08보다 작은값을 갖게 될 것이다.
Intall
- CentOS 5.4에서 수행함
- [다운로드] - simplesim-3v0d.tgz(바로가기 클릭)
- [참고] - http://www.simplescalar.com/
- [압축 풀기]
- $ tar -xvf simplesim-3v0d.tgz
- [빌드] - 압축해제 후 생성된 디렉터리로 이동한 후 config (pisa, pisabig, pisalit, alpha)
- $ cd simplesim-3.0
$ make config-pisa
$ make - 완료 후 "my work is done here..." 메시지 출력
- $ cd simplesim-3.0
- [설정] - .bash_profile에 실행파일, 컴파일러 경로 설정
- $ vi ~/.bash_profile
- PATH 뒤에 simplesim-3.0, 컴파일러 경로를 추가해줌(alias도 상관없음)
ex>PATH=$HOME/bin:$HOME/ss/simplesim-3.0
- [테스트] - 간단한 프로그램 작성 후 테스트
- sample code
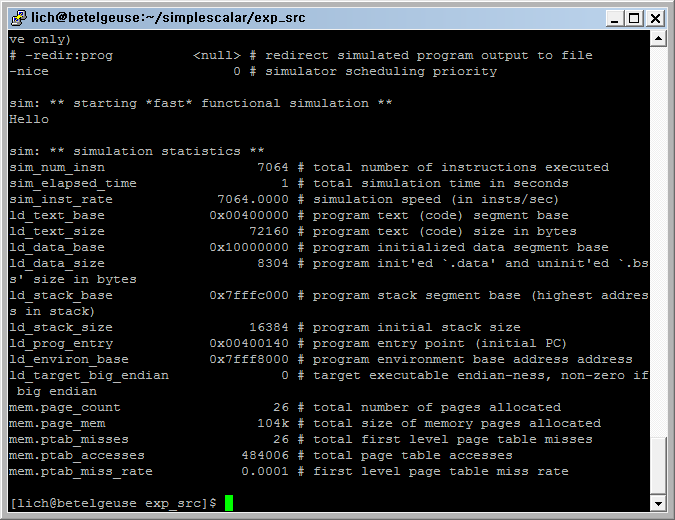
#include <stdio.h> int main(void){ printf("Hello\n"); return 0; } - compile - ssgcc로 alias 해놓았음
$ssgcc -o hello hello.c - 실행 결과
- sample code
Experiments
Mibench
- automotivate
| benchmarks\check list | compile | link | execute | correct result |
|---|---|---|---|---|
| basicmath | O | O | O | X |
| bitcounts | O | O | O | O |
| qsort | O | O | O | O |
| susan | O | O | O | O |
- consumer
| benchmarks\check list | compile | link | execute | correct result |
|---|---|---|---|---|
| jpeg | O | O | O | O |
| lame | X | - | - | - |
| mad | X | - | - | - |
| tiff | X | - | - | - |
| typeset | X | - | - | - |
- network
| benchmarks\check list | compile | link | execute | correct result |
|---|---|---|---|---|
| dijkstra | O | O | O | O |
| patricia | O | O | O | O |
- office
| benchmarks\check list | compile | link | execute | correct result |
|---|---|---|---|---|
| ghostscript | X | - | - | - |
| ispell | O | O | O | O |
| rsynth | X | - | - | - |
| sphinx | X | - | - | - |
| stringsearch | O | O | O | O |
- security - blowfish(ranlib path, cc)
| benchmarks\check list | compile | link | execute | correct result |
|---|---|---|---|---|
| blowfish | O | O | O | O |
| pgp | O | O | O | X |
| rijndael | O | O | O | O |
| sha | O | O | O | O |
- telecomm
| benchmarks\check list | compile | link | execute | correct result |
|---|---|---|---|---|
| CRC32 | O | O | O | O |
| FFT | O | O | O | O |
| adpcm | O | O | O | O |
| gsm | O | O | O | X |
Matrix Multiplication
- matrix의 크기를 L2 cache와 같게하여 프로그램을 수행해 보고 그 결과값을 확인한다.
- spec : 256 by 256의 int형 정방 행렬을 사용하며, cache는 64 KB L1 cache(32 KB L1 Data + 32 KB L1 Instruction), 256KB L2 cache를 사용하였다.
- result : 수행 결과, 총 8m15s의 시간이 소요되었고, CPI = 0.6824, IPC = 1.4654가 나왔다.
| L1 Instr | L1 Data | L2 | |
|---|---|---|---|
| access | 558324876 | 186063025 | 17039552 |
| misses | 356 | 16948720 | 449271 |
| miss rate | 0 | 0.0911 | 0.0264 |


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
result.jpg | manage | 31 K | 11 Jan 2011 - 08:46 | UnknownUser |
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r12 < r11 < r10 < r9 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r12 - 11 Sep 2014, AtulRahman
Ideas, requests, problems regarding Foswiki? Send feedback