
Seongseok Seo
Seongseok Seo entered UNIST in March, 2012, though he started to come to the lab about six months earlier, and worked as an intern in the lab during the winter break. He graduated from Ulsan University.
He is a recipient of Dongbu HiTek Best Paper Award at the 21st Korean Conference on Semiconductors (KCS), together with Yeonghun Jeong and Prof. Lee.
In 2014 he joined LG Electronics, in the CTO Division, in Seoul, Korea, as a hardware designer.


At a cozy Italian restaurant near Ulsan University.
In his masters thesis defense on Jan 9th, 2013, Toan presented an approach called Runtime Binary Translation (RBT) that can dynamically make use of the CGRA accelerator existing in a CGRA-based reconfigurable computing system to speedup the execution of application intermediate representation (IR) on top of a just-in-time (JIT) compiler. A simpler approach called Install-time Binary Translation (IBT) based on RBT is also proposed. Here is the abstract of the thesis. 😀
Nowadays, softwares are often distributed in form of some machine-independent intermediate representation (IR), because compared to machine-dependent native binary, the IR is more portable across a wide range of architectures, has better security, and contains richer semantic information. However, the problem of making use of the accelerator in a target machine to speedup the execution of the IR on top of a just-in-time compiler (JIT) is challenging, mainly because the discovery of compute-intensive kernels and the partitioning of the application to the kernel and sequential parts must be done based on the IR alone, without the access to the program source code as well as the kernel information in the IR.
In this work, we propose a Runtime Binary Translation (RBT) technique that can dynamically identify and translate kernels IR to Coarse-Grained Reconfigurable Array (CGRA) accelerator configuration, and offload the execution of the kernels onto the accelerator. Also, we simplify the RBT approach to make the Install-time Binary Translation (IBT) approach, which does the partitioning and the translation right at the install-time instead of at the runtime. Experimental results show that our RBT and IBT techniques can improve the runtime of the application IR by 1.44 times and 1.61 times, respectively, compare to the runtime on the JIT that does not support making use of the accelerator.

Runtime Binary Translation Virtual Machine Optimized Design
With Emacs you are expected to have it open 24/7 and live inside the program, almost everything you do can be done from there. You write your own extensions, use it for note taking, organisation, games, programming, shell access, file access, listening to music, web browsing. It takes weeks and weeks till you will be happy with it and then you will learn new stuff all the time. You will be annoyed when you don’t have access to it and constantly change your config. You won’t be able to use other people’s Emacs versions easily and it won’t just be installed. It uses Lisp, which is great. You can make it into anything you want it to be. (anything, at all)
With vim, it’s almost always pre-installed. It’s fast. You open up a file, do a quick edit and then quit. You can work with the basic setup if you are on someone else’s machine. It’s not quite so editable; but it’s still far better than most text editors. It recognises that most of the time you are reading/editing not typing and makes that portion faster. You don’t suffer from emacs pinkie. It’s not so infuriating. It’s easier to learn.
Even though I use Emacs all day every day (and love it) unless you intend to spend a lot of time in the program you choose I would pick vim
via http://stackoverflow.com/a/1433315
The best summary that I have seen on the differences between the two editors. Conclusion? You need both!
Congratulations, Toan!
Yesterday, January 9, Toan successfully defended his thesis on Runtime and Install-time Binary Translation for Reconfigurable Accelerators. Though there are some minor things he has to finish before he can get the approval signatures from the committee members, the thesis committee was in general agreement that he did a good job for a masters degree, based on his achievements during the graduate program and his thesis writing.
Now that he is seeking an industry career at the moment, the ICCL lab wishes him a good luck in his career and a good fortune too! 🙂

Important Notice
To students taking CSE211: Introduction to Programming Languages, in the 3rd term of 2012.
The required textbook for this course is changed to Concepts of Programming Languages by Robert W. Sebesta, 10th edition, Addison-Wesley. You can purchase the textbook at the campus bookstore or online.
Jongeun Lee, The Instructor
Seminar Schedule for September/October (Place is EB1 E204 unless noted otherwise.)
Cloud Random Access Network (C-RAN)
- Speaker: Dr. Saewoong Bahk, Seoul National University
- Date: September 19
- Title: Evolution of Wi-Fi on Cloud-RAN: Complementary Utilization of Unlicensed Spectrum
Flash Memory Technology
- Speaker: Dr. Taehoon Kim, Intel-Micron joint R&D team for memory devices
- Date: September 26
- Title: Challenges & Future Directions for Flash & Emerging Nonvolatile memories for 2D & 3D realization
Automotive
- Speaker: Dr. Seungyoung Ahn, KAIST
- Date: October 10
- Title: Future Green Transportation with Wireless Power Transfer Technology
Mobile Application Processor
- Speaker: Dr. Jeong-Ho Woo, Texas Instruments
- Date: October 23
- Title: Design Paradigm of Mobile Application Processor
Multiprocessor Architecture: Design and Implementation
- Speaker: Dr. Jongmyon Kim, University of Ulsan
- Date: October 24
- Title: Mobile Multimedia Supercomputer Design
Our paper titled “Software-Managed Automatic Data Sharing for Coarse-Grained Reconfigurable Coprocessors” is accepted as an oral presentation in the International Conference on Field Programming Technology (FPT) 2012, which will be held in Seoul, Dec 10~12.
Congratulations to those who participated in this work!
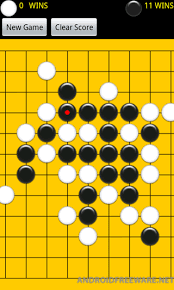
Yes, you read it correctly. It’s a rare combination of AI (Artificial Intelligence) and HW (Hardware) design skills, that is in want.
There is a national and an international competition that is scheduled around October, on FPGA designs that can play the “Connect-6” game. The connect-6 game is a variation of “Five-in-a-Row” (or Omok as is called in Korea), and the trick is that you have to make a hardware in FPGA that can play the game in real-time. The timing constraint is 1 min, and you have to come up with the best solution within the min — otherwise you’ll forfeit your chance to make a move.
*Highlights of this competition
- First place winner of the national level will be given a very prestigious MKE-ministry award (지식경제부 장관상).
- National level winners will enter the international level.
- International level winners will be recognized with cash prizes during an international conference (FPT), and their design summary will be published in the conference proceedings.
More details can be found in the conference website.
Sounds interesting? Contact the lab. Don’t worry if you don’t have any knowledge/experience with AI or HW design — not expected (but you should be at least a junior majoring in ECE).
Some dynamic elements are added to the front page, which now shows a slideshow instead of a random picture. The slideshow controls are also provided (previous, next, and pause/resume). The previous and next buttons are easy to spot, but where is the pause/resume button?
The answer is the page number.